Los de MistralAI se levantaron un día y subieron un magnet link (torrent) a x.com sin decir mucho más. Un par de días después levantaron EUR 400M en una ronda de inversión que los llevó a una valuación de $2B de dólares. Viendo lo bien que anduvo Mistral-7B, la comunidad de nerds hermosa que tenemos se metió en una carrera contra el tiempo para hacerlo funcionar y para empezar a evaluar que tan bien se comparaba con otros modelos abiertos y proprietarios. Resultó ser que funciona un 6% mejor GPT-3.5 en promedio y también que sale aprox. un 60% menos que OpenAI. O sea que finalmente sucedió .. un año después de que salió ChatGPT tenemos una versión abierta que podemos usar comercialmente que tiene el mismo o más rendimiento. En algunos lugares lo estan hosteando a más de 175 tokens/sec (un humano lee aprox. a ~10 tokens/sec)
Que dicen en twitter?
Jim Fan (NVIDIA, OpenAI):
My thoughts on Mistral's stellar rise:
— Jim Fan (@DrJimFan) December 11, 2023
- Successful setup: founded at good timing in the OSS vs closed AI debate, closed a $400M Series A at $2B valuation, and driven by a lean team.
- There're dozens of models coming out every month, but only a handful actually have staying… pic.twitter.com/OIAdvI4hVO
Andrej Karpathy (OpenAI, Tesla)
Official post on Mixtral 8x7B: https://t.co/ce0ZjHhLVn
— Andrej Karpathy (@karpathy) December 11, 2023
Official PR into vLLM shows the inference code:https://t.co/vJbmDG9RhG
New HuggingFace explainer on MoE very nice:https://t.co/lTaNCONUeI
In naive decoding, performance of a bit above 70B (Llama 2), at inference speed… https://t.co/OMSTfYXVsE
que si lo dejas un rato te adivina el modelo viendo el params.json
New open weights LLM from @MistralAI
— Andrej Karpathy (@karpathy) December 8, 2023
params.json:
- hidden_dim / dim = 14336/4096 => 3.5X MLP expand
- n_heads / n_kv_heads = 32/8 => 4X multiquery
- "moe" => mixture of experts 8X top 2 👀
Likely related code: https://t.co/yrqRtYhxKR
Oddly absent: an over-rehearsed… https://t.co/8PvqdHz1bR pic.twitter.com/xMDRj3WAVh
Soumith Chintala (PyTorch, MetaAI)
It can be unintuitive why the Transformer-style MoE (in Mixtral/GPT4) has inference benefits.
— Soumith Chintala (@soumithchintala) December 11, 2023
Dima simplifies it with a clear explanation showcasing that MoE help inference once there's sufficient volume of requests (which hopefully are diverse enough that they don't hit the same… https://t.co/XPPcp81bhy
Nathan Lambert (Allen Institute for AI)
Mixture of experts (MoE) models are less conceptually intimidating than people think (myself included, until this weekend).
— Nathan Lambert (@natolambert) December 11, 2023
The key intuition is that in the feedforward parts of the model (not the attention blocks) the router selects an expert layer for every token. Routing is… pic.twitter.com/HAMv56G7iB
Que anunció MistralAI?
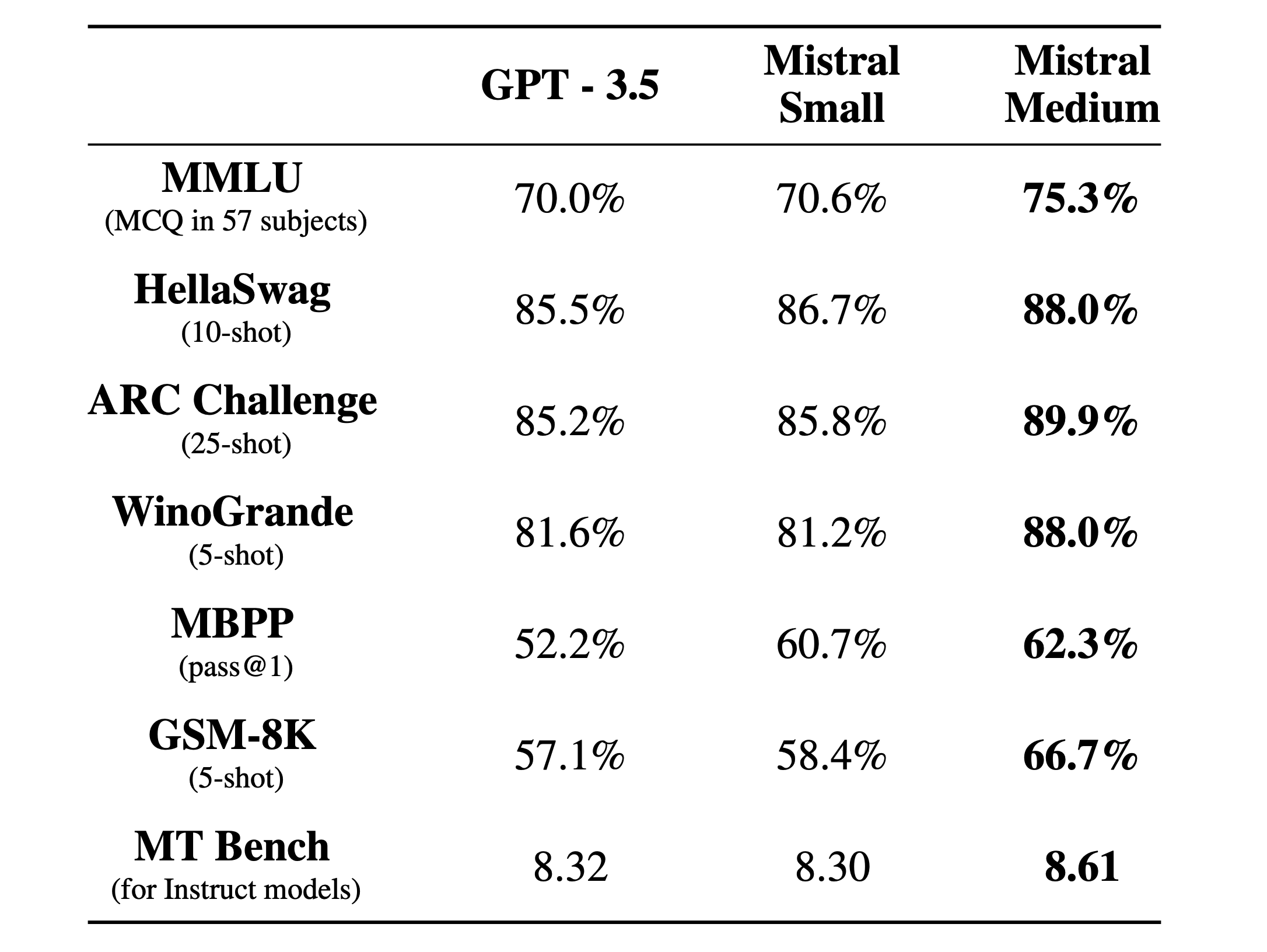
Dos cosas. Primero sacaron un blog post sobre Mixtral-8x7B, su primer modelo usando “Mixture of Experts” (MoE). Lo podés ver acá. Después anunciaron “La plateforme” donde ” (their) first AI endpoints are available in early access”. Ahi vemos dos modelos: mistral-small que es su modelo MoE-8x7B y después mistral-medium que es un modelo proprietario (como OpenAI o Anthropic) que está cerca de GPT-4 en performance, pero al menos 4 veces mas barato. Acá esta el anuncio.
Donde podemos probar Mixtral-8x7B?
Hay una banda de lugares, podés irte a HuggingChat, al Chatbot Arena (LMSYS), o a Together.ai.
Acá hay un review de los lugares donde lo tenés al modelo como una API.
Mixtral API pricing by provider:
— interstellarninja (@intrstllrninja) December 13, 2023
1. @MistralAI
input: 0.6€ / 1M tokens
output: 1.8€ / 1M tokens
2. @togethercompute
$0.6 / 1M tokens
3. @perplexity_ai
input: $0.14 / 1M tokens
output: $0.56 / 1M tokens
4.@anyscalecompute
$0.50 / 1M tokens https://t.co/pI4B5VPpv3
Y qué tan bien funciona?
Arena live update: 1000+ new votes have just rolled in for Mixtral-8x7b!
— lmsys.org (@lmsysorg) December 12, 2023
Excitingly, Mixtral-8x7b is overtaking Tulu-2-70B as the top open model and achieving ~50% winrate against gpt-3.5-turbo.
Let's cast more votes and challenge it with the toughest prompt at… https://t.co/irFddypBYp pic.twitter.com/t5l2cLkmSR
A toolkit for inference and evaluation of ‘mixtral-8x7b-32kseqlen’ from Mistral AI
Qué es todo esto de los “Mixture of Experts” (MoE)?
Dos lindos artículos, uno por Huggingface acá, y otro por Nathan Lambert acá.